爬虫基础库使用
将对一些爬虫会使用到的基础库进行一定的记录
urllib
用于实现请求的发送
一般有三个库被使用
request:用于发送请求
parse:用于URL的处理
error:异常处理
发送请求
urllib.request模块提供最基本构造HTTP请求功能
- urlopen
import urllib.request
response = urllib.request.urlopen("http://119.23.18.158")#使用urlopen来模拟打开网页
print(response.read().decode("utf-8"))#输出后可以看到该页面源码
print(response.getheader('server'))
print(response.version)
print(response.reason)
print(response.debuglevel)可以使用一些该类型对象的方法或者属性可以查看更多的信息
如果想传递一些参数,可以查看urlopen的api,
比如参数data可用于POST型的传递参数
参数timeout用于响应时长(即多久没有得到服务器响应就报错)
这里可以使用timeout以及error模块来进行报错处理
- Request
URLopen可以简单的实现请求的发起,但如果要使用更复杂的请求就需要使用Request类(比如加入header)
比如
request1=urllib.request.Request('http://119.23.18.158')#Request类的实例化
response = urllib.request.urlopen(request1)
#这样也就可以实现请求看一下Request的构造方法:
class urllib. request. Request ( url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
除了第一个url其它都是可选参数
第二个参数 data 如果要传,必须传 bytes(字节流)类型的 如果它是字典,可以先用
urllib.parse 模块里的 urlencode ()编码第 个参数 headers 是一个字典,它就是请求头,我们可以在构造请求时通过 headers 参数直
接构造,也可以通过调用请求实例的 add_header ()方法添加添加请求头最常用的用法就是通过修改 User-Agent 来伪装浏览器,默认的 User-Agent 一-
Python-urllib ,我们可以通过修改它来伪装浏览器 比如要伪装火狐浏览器,你可以把它设 置为Mozilla/s.o (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
第四个参数 origin_req_host 指的是请求方的 host 名称或者 IP 地址
第五个参数 nveri iable 表示这个请求是否是无法验证的,默认是 False ,意思就是说用户没
有足够权限来选择接收这个请求的结果 例如,我们请求 HTML 文档中的图片,但是我
们没有向动抓取图像的权限,这时 unverifiable 的值就是 True第六个参数 method 一个字符串 ,用来指示请求使用的方法,比如 GET POST PUT
构建多个参数如下图所示
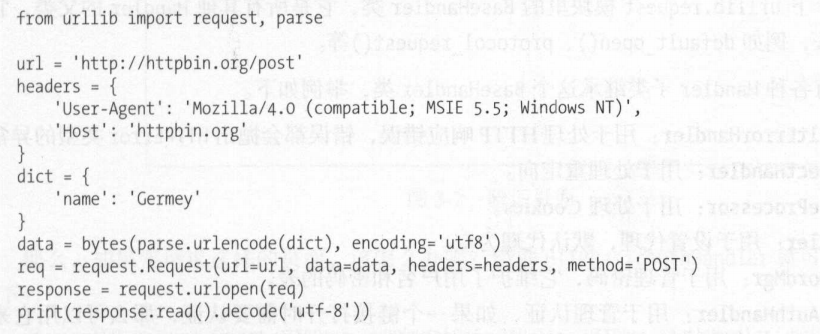
handler
一些高级请求如cookie请求的构造需要用到Handler了,handler是urllib中request模块中的一组类,BaseHandler是所有Handler的父类,其它的子类有其更细的公能:

这里还有一个OpenerDirector类比较重要,与之前的urlopen类似,而在这里我们用handler来构建opener
- 有的时候我们会遇见用js写的验证,需要验证用户名和密码
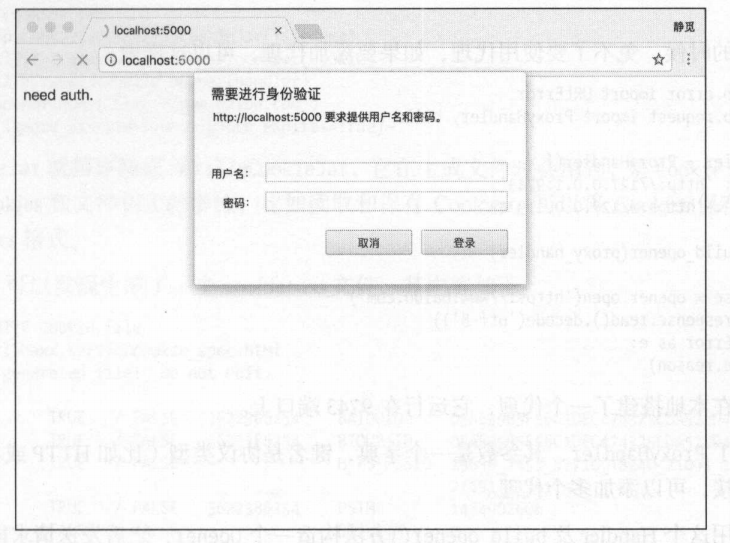
使用HTTPBasicAuthHandler就可以完成

填写username等信息后先初始化一个HTTPasswordMgrWithDefaultRealm对象,再实例化HTTPBasicAuthHandler对象,以之前的HTTPasswordMgrWithDefaultRealm对象为参数,这样就建立了一个处理验证的handler。
接下来用这个handler使用build_opener来构造一个opener,再用opener调用open就可以打开链接完成验证了
- 代理

- cookie
处理cookie的时候也会使用到handler

如果想要将cookie储存为文本文件,只需要将CookieJar换为MozillarCookieJar(是CookieJar的子类)用来处理与cookie相关的文件相关事件

LWPCookieJar也可以保存读取cookie但格式为LWP,声明时按需选取即可
当我们需要使用被存储的cookie时,

- 异常处理
urllib 的error模块会处理由调用request模块产生的异常
- URLError
由request调用产生的异常都可以使用URLError来解决
- HTTPError
是URLError的子类,专门处理http请求错误的error,比如认证请求失败,有三个属性

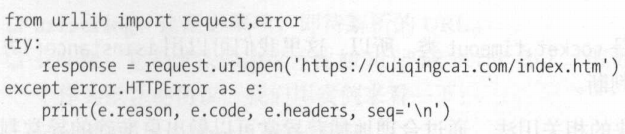

解析链接
urllib库中的parse模块定义了处理URL的标准接口,可以实现URL的抽取合并以及链接转换
- urlparse
可以实现url的识别和分段,下面看一段代码
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html;user?id=4#comment')
print(type(result),result)可以看到结果
<class 'urllib.parse.ParseResult'> ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=4', fragment='comment')


- urlunparse
与urlparse对应,参数是一个可迭代对象,长度必须为6,

运行结果为
https://www.baidu.com/index.html;user?id=4#comment- urlsplit
和urlparse很类似,只是少了一个参数,不再单独解析params,放入了path中
- urlunsplit
类似urlunparse
记录到这里我有点迷茫,这些其实在真的爬虫中都是用不到的东西,urllib库里的东西基本都被requests库里的替代了,那我费这么长的时间学有啥用呢,我悟了,urllib看看就行,爬虫只是一个工具,不搞原理的东西了,能写出来就行,从这里停止记录
- 用于get请求构造序列化以及反序列化的分别为:
urlencode()
parse_qs(),parse_qsl()
具体不表
- queote()
将内容转换为url编码格式
- unquote()
URL格式解码
robot协议
- robot协议决定了网站哪些页面允许爬虫爬取,哪些不允许,一般是由robot.txt文件来管理,放在网站根目录下或者和index页面放在一起,robot.txt一般写法如下:

这里的意思是所有都不允许,只允许/public/文件夹下的
- urllib使用robotparser模块对robot.txt进行解析
主要使用了RobotFileParser类,


requests
一般来说urllib使用并不多,而requests库的使用时很多的,这是一个强大的库,我们可以依靠他完成很多操作
基本用法
- GET请求
构建get请求:
import requests
r=requests.get('https://www.baidu.com/')
print(r.text)
print(r.cookie)
print(r.status_code)通过get来发起get请求,获得了返回值r,可以对r进行一系列操作

r=requests.get('http://www.httpbin.org/get')
print(r.text)相应结果为:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5f8184fe-31632cd76578202c2104fe09"
},
"origin": "223.129.4.193",
"url": "http://www.httpbin.org/get"
}我们成功的发起请求返回的结果中包括请求头,URL,IP等信息
当我们要在请求时增加参数时,使用下面的方法,我们使用一个字典来储存我要传递的参数,在get时添加就好
data={
'name':'aaa',
'age':22
}
r=requests.get('http://www.httpbin.org/get',params=data)
print(r.text)传递后可以看到返回的时候多了两个参数
{
"args": {
"age": "22",
"name": "aaa"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5f81860b-27efd9e81e182e3166e8e817"
},
"origin": "223.129.4.193",
"url": "http://www.httpbin.org/get?name=aaa&age=22"
}也就是说我们传递的url被自动构造成了一个带有get请求的url

import requests
r=requests.get('http://www.httpbin.org/get')
print(type(r.text))
print(r.json())
print(type(r.json()))<class 'str'>
{'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'www.httpbin.org', 'User-Agent': 'python-requests/2.22.0', 'X-Amzn-Trace-Id': 'Root=1-5f8186e7-6fffeeeb0af3cfa32351c4ce'}, 'origin': '223.129.4.193', 'url': 'http://www.httpbin.org/get'}
<class 'dict'>可以看到格式变化
- 抓取二进制数据
当我们抓取网页的时候我们得到的返回是一个HTML文档,但当我们需要抓取图片,音乐等时,我们要知道,这些文件是二进制格式的
这里给出一个抓取图片的实例:
r=requests.get("https://github.com/favicon.ico")
print(r.text)
print(r.content)这是抓取github的站点图标

我们将其保存就可以在文件夹中看到图标
- 添加header
使用header来传递头信息,比如我们防止反爬要更改User-Agent
- POST请求
和get方式很像,只是是通过post向服务器端传输数据
import requests
data={
name='hhh'
age=6
}
r=requests.post("http://httpbin.org/post",data=data)
print(r.text)可以得到如下返回:
F:\python\python.exe F:/python_work_place/spider_test/forward_test.py
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "6",
"name": "hhh"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "14",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0",
"X-Amzn-Trace-Id": "Root=1-5f8810f4-71311a454c6c90486810fdfe"
},
"json": null,
"origin": "223.129.4.231",
"url": "http://httpbin.org/post"
}
Process finished with exit code 0
可以看到我们使用form表单上传了我们的参数
- 响应
在请求成功后得到了响应,我们可以使用.text,.content等来获取响应内容,也可以获得cookie或者头参数等,实例如下:


高级用法
我们可以使用requests来模拟提交文件,比如
import requests
file={'file':open('a.txt','rb')} #上传的file的文件格式
r=requests.post("http://httpbin.org/post",files=file)
print(r.text)就可以实现自动上传文件
同时还有对cookie的操作
import requests
headers={
'Cookie':'_zap=fc99e39d-d13b-4839-8cf0-76ec70f3bc83; _xsrf=7XVuHOKM3FdxZfQNpIXA3R5gO884m8GN; d_c0="ALAsIZyEKRCPTjrPS9wsjOspI-w5ABEmkvA=|1570444133"; __utmv=51854390.100--|2=registration_date=20180614=1^3=entry_date=20180614=1; __utma=51854390.138991721.1572940125.1576250154.1576303660.7; _ga=GA1.2.138991721.1572940125; z_c0="2|1:0|10:1591710317|4:z_c0|92:Mi4xblNSTkNnQUFBQUFBc0N3aG5JUXBFQ1lBQUFCZ0FsVk5iT0RNWHdDbjlOVGMtTVo2bUxkSlJrZ2dyeW94ZkxkMFN3|9cab263c34306c8af64178b0d9c9330f9871c4d5e26a8a9093b293ba98bed6bd"; tst=r; q_c1=40bb646872384d60882f2072981be334|1600770724000|1572940120000; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1602345002,1602386153,1602467925,1602754438; SESSIONID=L40MZ7VrYxOQ4XYatS3x5LdGSxYLQSGAVv3KwP5QuFA; JOID=Wl0TBE7yjCkclRM2Yv28tZmR0Kd9s7sYU8IpYxGm-WVMo0ZiAHWZokyVHTRhx9EGtx0aSqDDvpjg5OZuY5JyOGU=; osd=VlkSAUr-iCgZkR8yY_i4uZ2Q1aNxt7odV84tYhSi9WFNpkJuBHScpkCRHDFly9UHshkWTqHGupTk5eNqb5ZzPWE=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1602755346; KLBRSID=ed2ad9934af8a1f80db52dcb08d13344|1602755346|1602754433',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#通过从浏览器中找到自己登陆后的cookie,复制到这里,同时修改user-agent就可以实现登陆知乎,如果没有User-Agent则会被反爬,得到400
r=requests.get("https://www.zhihu.com",headers=headers)
print(r.cookies) #可以看出是字典格式
for key,value in r.cookies.items():
print(key+'=='+value)
print(r.text)- 会话维持
session对象,让我们可以方便的维持一个会话,让我们对网站的后续操作更加便捷,使用session我们可以做到模拟同一个会话而不用考虑cookie问题,通常用于模拟登陆成功后的方便进行下一步操作


这里我们可以看到,不能获取到我们想要的cookie数据,为空,这就是因为这其实是两个会话,第二个会话并不能访问到第一个会话的cookie

这就是使用session就可以维持会话,可以得到最开始设置的cookie
- SSL证书验证
当发送http请求时,会检查ssl证书,requests库使用verify参数来控制是否检查该证书,比如当我们访问12306时,因为其证书没有被认证,所以会返回一个非安全警告页面:**现在验证12306并无证书问题,只是做一个例子**

要避免这个错误只需要在get请求中加上一个verify=False即可,
import requests
url="http://www.12306.cn"
r=requests.get(url,verify=false)
print(r.status_code)
print(r.text)这样就可以输出正常状态码,但此时会有一个warning,我们可以屏蔽掉他


- 代理设置
很多时候对于我们简单的测试内容可以很轻易的爬取,但当开始大规模数据采集的时候很容易被网站反爬虫策略所阻止,对于频繁的大规模请求,可能弹出验证码,跳转登录,或者直接封ip。所以我们需要设置代理
对于requests库设置代理很简单,使用proxies参数设置代理,示例如下
import requests
proxies={
"http":"http:127.0.0.1:1080",
"https":"http:127.0.0.1:1000"
}
url="http://www.12306.cn"
r=requests.get(url,proxies=proxies)
print(r.status_code)这样就设置了代理服务器,这里的设置的是本地服务器的不同端口作为代理,
若代理要使用HTTP Basic Auth(http 基础认证)可以使用如下格式: http://user:password@host:port的格式如:
proxies={
"http":"http://admin:1232@127.0.0.1:1080",
"https":"http://admin:1232@127.0.0.1:1000"
}requests也支持Sockts代理

- 超时设置
使用timeout参数,如果在规定时间内没有相应则报错,timeout是从发出请求开始计时,到响应返回服务器,
import requests
url="http://www.12306.cn"
r=requests.get(url,timeout=1)#timeout为1s默认为none,即没有超时限制
- 身份认证
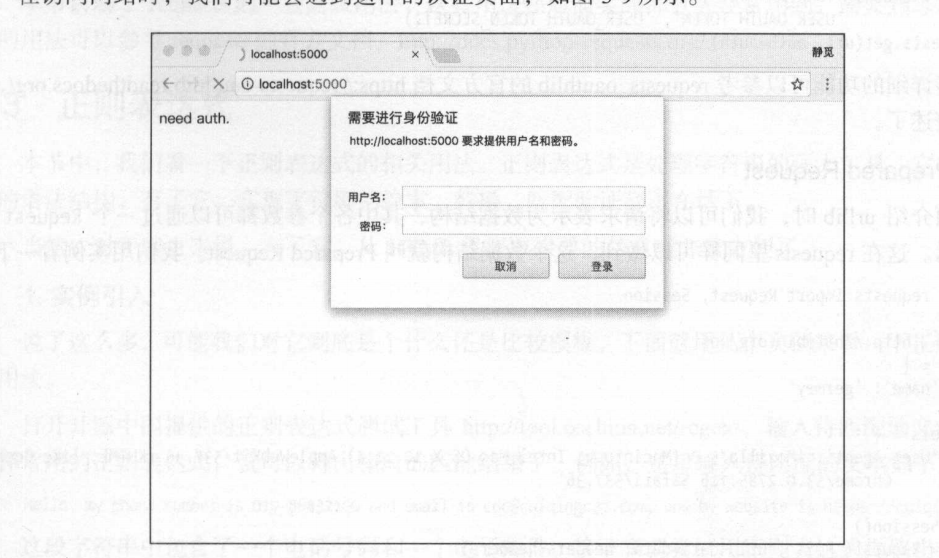
有的时候会遇见这样的身份验证(http基础验证)


注意传的是元组

- prepared request
当我们需要传递很多歌参数时直接在请求中添加参数代码结构不雅观其实我觉得没问题
我们使用一个数据结构Prepared Request,将所有参数通过一个Request对象来表示。参考实例:
from requests import Request,Session
url="http://www.zhihu.com"
s=Session() #实例化session对象
data={
"name":"hhh",
"age":12
}
headers={
'User-Agent':"xxxxxxxxxxx"
}
req=Request('POST',url,data=data,headers=headers)#实例化Requset对象req,用于储存参数
pre=s.prepare_request(req) #使用session的prepare_requests方法将其转化为一个prepare request对象
r=s.send(pre) #调用send,发送数据即可
正则表达式
正则表达式是用于处理字符串的一系列特定语法,在爬虫以及其他领域有着很重要的作用
常用匹配规则:
\w 匹配字母,数字以及下划线
\W 匹配不是字母,数字以及下划线的字符
\s 匹配任意空白字符串,等价于[\t\n\r\f]
\S 匹配任意非空字符串
\d 匹配任意数字,等价于[0-9]
\D 匹配任何非数字字符
\A 匹配字符串开头
\Z 匹配字符串结尾,如果存在换行则只匹配到换行前的结束字符串
\z 匹配字符串结尾,如果存在换行,同时还会匹配换行符
\G 匹配最后匹配完成的位置
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配一行字符串的开头
$ 匹配一行字符串的结尾
. 匹配任意字符串,除换行符,当re.DOTALL标记被指定,则可以匹配包括换行符的任意字符
[…] 用来表示一组字符,单独列出,比如[ahb]匹配a,m或者k
[^…] 不在[]中的字符,如[ ^a,b,c]匹配除a,b,c以外的字符
* 匹配0个或者多个表达式,
+ 匹配1个前面或多个表达式
? 匹配0或1个前面的正则表达式定义的片段,非贪婪方式
{n} 精确匹配到n个前面的表达式
{n,m} 匹配n到m次由前面正则表达式定义的方式,贪婪方式
a|b 匹配a或b
( ) 匹配括号内的表达式,也表示一个组
对于re库来说有几个常用于正则表达式匹配的函数
match
第一个参数是正则表达字符串,第二个参数是需要匹配的字符串,从初始位置匹配,
当匹配成功后返回的对象一般调用两个方法,一个是group,会返回匹配到的字符串,如果在匹配的正则表达式中使用了()则小括号中匹配到的可以使用group(1),group(2)来表示,另一个方法是span,会表达出匹配到的字符串长度
要注意两个地方,当我们使用任意匹配时,有贪婪匹配和非贪婪匹配,
- 贪婪:
.*这里的.代表匹配任意字符一次,代表匹配匹配前面的字符无限次,组合在一起就可以匹配任意多个字符了,这是一种贪婪匹配,意思是比如一个字符串:aaa 123a,我们想要匹配到他,使用.\,^aaa/s.*(\d+)a$这里的想法是group(1)中能匹配到所有的数字,但最后发现只能匹配到一个3,就是因为是贪婪匹配,.*会尽可能多的匹配,1,2都在其中,只留了3给(\d), - 非贪婪匹配就是
.*?,这样匹配对上述的字符串就能匹配到想要的123,因为只要遇见了后面所需要的\d就停止匹配。
- 贪婪: